Notion RAG 검색 시스템 구축

안녕하세요, AIPD팀 문광석 입니다.
업무를 하다 보면 Notion에 정리해 둔 내용이 기억나지 않아 검색하느라 시간을 허비하는 경우가 많습니다. 이번 포스팅에서는 이러한 불편함을 해소하기 위해 Go와 Gemini를 활용하여 나만의 'AI 비서(RAG 시스템)'를 구축해 본 경험을 공유하고자 합니다.
현대 지식 근로자들에게 Notion은 제2의 뇌와 같습니다. 하지만 데이터가 쌓일수록 "분명 어딘가에 적어뒀는데..." 하며 헤매는 시간이 길어집니다. Notion의 내장 검색은 키워드 매칭 방식이라, 문맥이나 의미를 파악하는 질문(Semantic Search)에는 한계가 명확하기 때문입니다.
이 프로젝트는 Notion을 단순한 저장소가 아닌, 살아있는 개인 지식 베이스로 활용하기 위해 시작되었습니다. Go 언어의 강력한 동시성 모델로 데이터를 수집하고, Google Gemini의 임베딩과 LLM을 활용해 RAG(Retrieval-Augmented Generation) 시스템을 CLI 도구로 구현했습니다.
한마디로 설명하면 내가 노션에 기록한 모든 내용을 기억하고 있는 AI 비서를 만드는 것입니다.
예를 들어, "나 8월 23일에 무슨 업무 했었지?" 라고 물어보면, AI가 내 노션 페이지를 뒤져서 그날의 업무 기록을 찾아 요약해 줍니다. 일일이 페이지를 들어가서 날짜를 확인할 필요가 없죠.
물론, 이미 훌륭한 'Notion AI' 서비스가 존재합니다. 하지만 이 프로젝트의 핵심은 내 데이터를 내 입맛대로, 그리고 무엇보다 무료(또는 아주 저렴하게)로 다루는 것에 있습니다.
문서를 예쁘게 꾸미거나 새로운 양식을 만드는건 Notion AI가 훨씬 잘합니다. 우리는 '검색'과 '질문'에 집중해 봅시다!
이렇게 직접 구현하면 다음과 같은 매력이 있습니다.
다음은 실제로 프로그램을 사용하여 원하는 데이터를 검색한 예 입니다.

• 자동Notion 동기화: Notion API를 통해 모든 페이지를 자동으로 가져와서 벡터화
• Gemini 임베딩: Google Gemini Embedding API를 사용한 고품질 텍스트 임베딩
• 유사도 기반 검색: Cosine Similarity를 사용한 정확한 문서 검색
• RAG 기반 답변: Gemini를 사용한 컨텍스트 기반 답변 생성
• Go: 페이지를 크롤링하고 벡터화하기 위해 Goroutine과 Channel을 활용한 병렬 처리를 활용
• chromem-go: 복잡한 설정 없이 바이너리에 내장 가능한 로컬 임베딩 벡터 DB입니다. 배포 용이성을 위해 선택했습니다.외부 벡터 DB 서버를 띄우지 않아도 되기 때문에,
CLI 도구 + 개인 프로젝트에 특히 잘 맞았습니다.
• Google Gemini (Embedding & 2.5 Flash): 긴 컨텍스트 윈도우와 빠른 처리 속도, 그리고 우수한 한국어 처리 능력을 갖추고 있으며 무엇보다 무료 또는 저렴한 가격으로 사용 가능하여 개인 프로젝트에 최적입니다.
Gemini 모델 정보
프로젝트 시작 또는 사용을 위해서는 먼저 사전준비가 필요했습니다.
Gemini API 사용을 위한 Key 발급과 프로그램이 Notion 문서에 접근할 수 있도록 키를 발급하고 권한을 부여하는 일 입니다.
이 프로젝트에서는 텍스트를 벡터로 변환하는 Embedding 모델과 답변을 생성하는 Generative 모델 모두 Google Gemini를 사용합니다. Google AI Studio를 통해 무료로 API 키를 발급받을 수 있습니다.
Google AI Studio 에 접속하여 구글 계정으로 로그인합니다.
좌측 상단 메뉴에서 Get API key 버튼을 클릭합니다.
Create API key 버튼을 클릭합니다.
Create API key in new project를 선택합니다. (기존 Google Cloud 프로젝트가 있다면 연결해도 무방합니다.)
키 만들기를 선택하여 키를 생성합니다.
생성된 키는 프로그램 설정에서 사용합니다.
💡 Free Tier(무료 등급) 주의사항: Google AI Studio의 무료 등급은 개인 프로젝트에 충분한 사용량을 제공하지만, 분당 요청 횟수(RPM) 제한이 있습니다.
• 이 프로젝트의 Go 코드에 **Rate Limit 처리(30초 대기 로직)**가 포함된 이유가 바로 이 무료 등급 제한을 안전하게 준수하기 위함입니다.
• 별도의 결제 등록 없이도 바로 사용 가능하므로, 토이 프로젝트나 개인 지식 베이스 구축에 최적화되어 있습니다.
크롤러가 Notion 페이지에 접속하기 위해서는 API 키를 발급해야 합니다. 또한 특정 페이지에 명시적으로 권한을 부여해야만 크롤러가 데이터를 읽을 수 있습니다.
Notion My Integrations 페이지에 접속합니다.
새 API 통합 버튼을 클릭합니다.
이름을 입력하고(예: My Knowledge RAG), Type은 프라이빗 으로 설정하여 생성합니다.
발급된 API Key 는 프로그램 설정에서 사용됩니다.
이 과정을 건너뛰면 API는 404 Not Found 혹은 빈 리스트를 반환합니다.
RAG 시스템에 연동하고 싶은 최상위 Notion 페이지로 이동합니다.
우측 상단의 ... (더보기) 아이콘을 클릭합니다.
메뉴 하단의 연결을 확인합니다. 그후 연결 추가하기 버튼을 클릭합니다.
방금 생성한 Integration 이름(My Knowledge RAG)을 검색하여 선택합니다.
확인을 누르면 연결이 완료됩니다.
💡 중요 팁:
• 최상위 페이지에 권한을 부여하면, 그 하위에 있는 하위 페이지에도 자동으로 권한이 상속됩니다. 따라서 지식 베이스의 루트 페이지 하나만 연결하면 됩니다.
• 만약 루트페이지를 만들기 싫다면 이 프로젝트와 연동할 각 페이지의 루트에만 권한을 부여해 주면 됩니다.
이 시스템의 핵심은 Notion API의 느린 응답 속도와 Gemini API의 처리 속도 차이를 극복하는 것입니다. 이를 위해 Producer-Consumer 패턴을 도입했습니다.
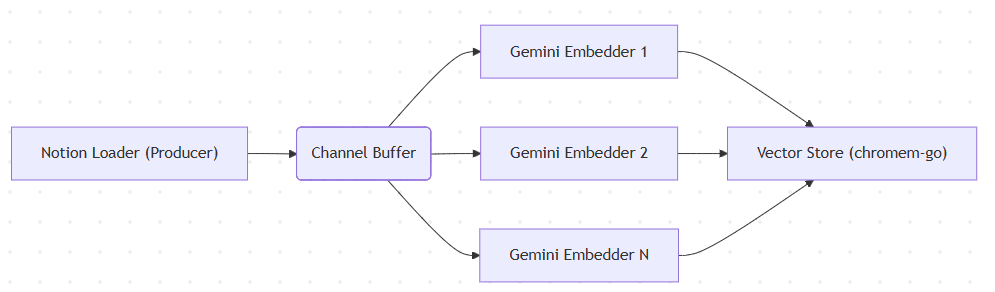
Producer: Notion API에서 페이지를 비동기로 가져와 텍스트를 청킹(Chunking)합니다.
Channel: 처리된 문서 조각을 버퍼 채널로 보냅니다.
Consumer Pool: 여러 개의 Goroutine(Worker)이 채널에서 문서를 꺼내 병렬로 임베딩을 생성하고 DB에 저장합니다.
가장 중요한 성능 최적화 부분입니다. sync.WaitGroup과 Channel을 사용하여 데이터 수집과 임베딩 생성을 동시에 수행합니다.
func processDocumentsPipeline(ctx context.Context, loader *notion.Loader, geminiKey string, store *db.Store, workerCount int) error {
// 1. 문서 전달용 채널 생성 (버퍼 크기는 워커 수의 2배)
docChan := make(chan *models.Document, workerCount*2)
var wg sync.WaitGroup
// 2. Consumer: 임베딩 워커 풀 가동
for i := 0; i < workerCount; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
// 각 워커별 독립적인 Gemini 클라이언트 생성 (Rate Limit 분산)
embedder, _ := embedding.NewEmbedder(ctx, geminiKey)
defer embedder.Close()
for doc := range docChan {
// 임베딩 생성 및 DB 저장 로직
vector, err := embedder.EmbedText(doc.Content, "RETRIEVAL_DOCUMENT")
if err == nil {
doc.Vector = vector
store.AddDocument(ctx, doc)
}
}
}(i)
}
// 3. Producer: Notion 데이터 스트리밍
go func() {
// Notion API를 순회하며 페이지를 청킹하여 채널로 전송
loader.FetchAllPagesStream(ctx, docChan)
}()
// 4. 모든 작업 완료 대기
wg.Wait()
return nil
}
구현 포인트:
• 독립된 클라이언트: 각 워커가 독립적인 Gemini 클라이언트 인스턴스를 가져 API 연결을 효율적으로 관리합니다.
• Backpressure 제어: 채널 버퍼를 통해 Notion API와 임베딩 API 간의 속도 차이를 조절합니다.
• Rate Limit 처리: 임베딩 생성 중 429 Too Many Requests 발생 시, 지수 백오프(Exponential Backoff) 대신 고정 딜레이(30초) 후 재시도하는 로직을 embedding 패키지에 구현하여 안정성을 확보했습니다.
데이터를 잘 쌓았더라도 검색이 부정확하면 무용지물입니다. 정확도를 높이기 위해 다음과 같은 전략을 사용했습니다.
청킹(Chunking): Notion 페이지를 1,000자 단위로 자릅니다. 너무 짧으면 문맥이 잘리고, 너무 길면 검색 정확도가 떨어지기 때문입니다.
유사도 필터링: 코사인 유사도(Cosine Similarity)가 0.7 이상인 문서만 컨텍스트로 사용합니다. 관련 없는 문서가 LLM에 들어가면 환각(Hallucination)을 유발할 수 있습니다.
// db/store.go
func (s *Store) Search(ctx context.Context, queryVector []float32, topK int) ([]*models.Document, error) {
results, _ := s.collection.QueryEmbedding(ctx, queryVector, topK, nil, nil)
var documents []*models.Document
for _, result := range results {
// 노이즈 제거를 위한 임계값 설정
if result.Similarity < 0.7 {
continue
}
// ... 결과 매핑 ...
}
return documents, nil
}
검색된 문서를 바탕으로 Gemini가 답변하도록 명확한 페르소나와 제약 조건을 부여합니다.
// rag/search.go
prompt := fmt.Sprintf(`당신은 나의 Notion 개인 비서입니다.
아래 [Context]를 바탕으로 질문에 답하세요.
모르는 내용은 지어내지 말고 "정보가 부족하여 알 수 없습니다"라고 답하세요.
[Context]
%s
[Question]
%s`, contextText, question)
이제 프로그램 구현이 완료되었으니 기능을 직접 사용해 보도록 하겠습니다.
우선 설정파일에 아까 발급받은 키를 입력해 줍니다.
notion_api_key와 gemini_api_key 를 입력합니다.

그리고 프로그램의 명령어를 확인하기 위해 help 명령어를 실행합니다.
goc-notion-rag.exe -help

우선은 데이터 로드를 위해서 reload 명령어를 실행합니다.
goc-notion-rag.exe -reload
그러면 데이터 로드를 시작합니다.
데이터 로드가 진행되면서 임베딩이 동시에 진행됩니다.
데이터가 완전히 로드될 때 까지 기다립니다.

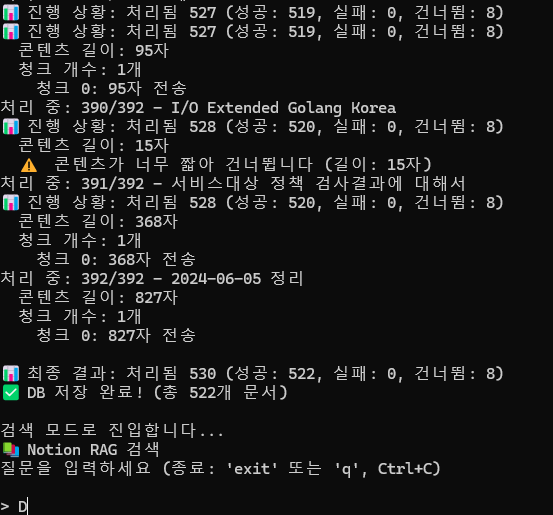
데이터 로드 및 임베딩 작업이 완료되면 자동으로 검색모드로 진입합니다.
또한 데이터 로드가 완료되면 임베딩 데이터가 로컬 환경에 저장된 것을 확인할 수 있습니다.

다음은 실제 RAG 기능을 테스트 해보도록 하겠습니다.
실제 제가 작성한 노션 데이터를 기반으로 검색을 해보겠습니다.
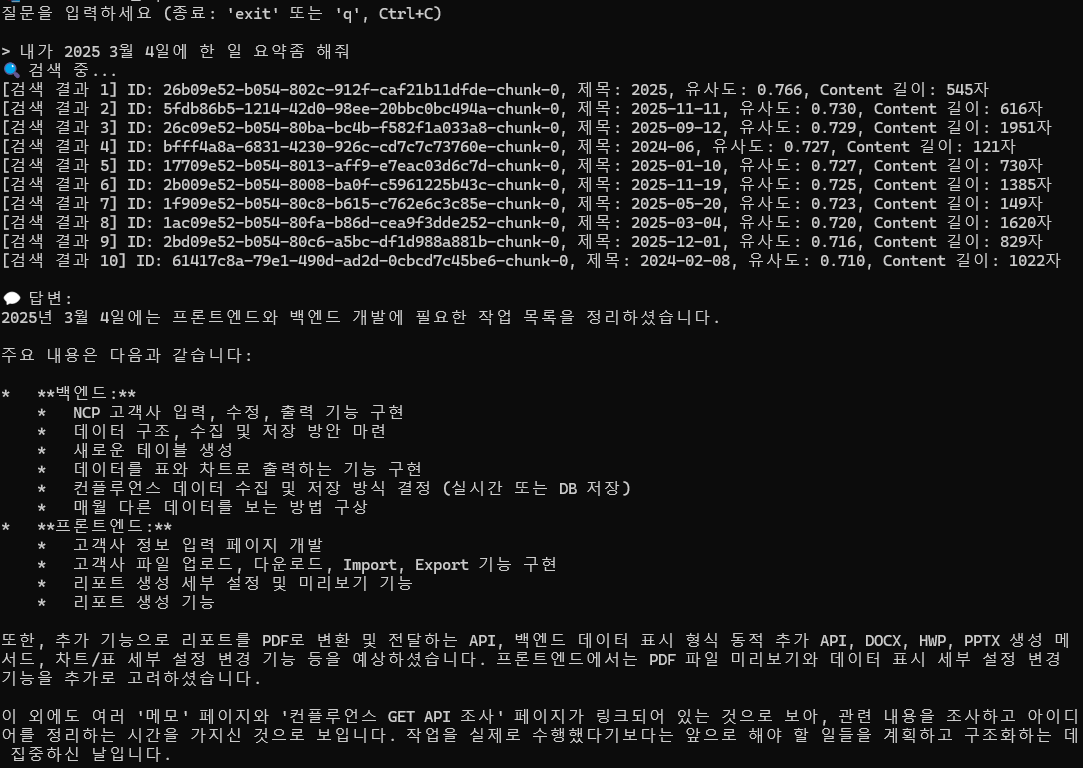
내가 2025 3월 4일에 한 일 요약좀 해줘
내가 본적 있는 프리큐어 시리즈 알려줘
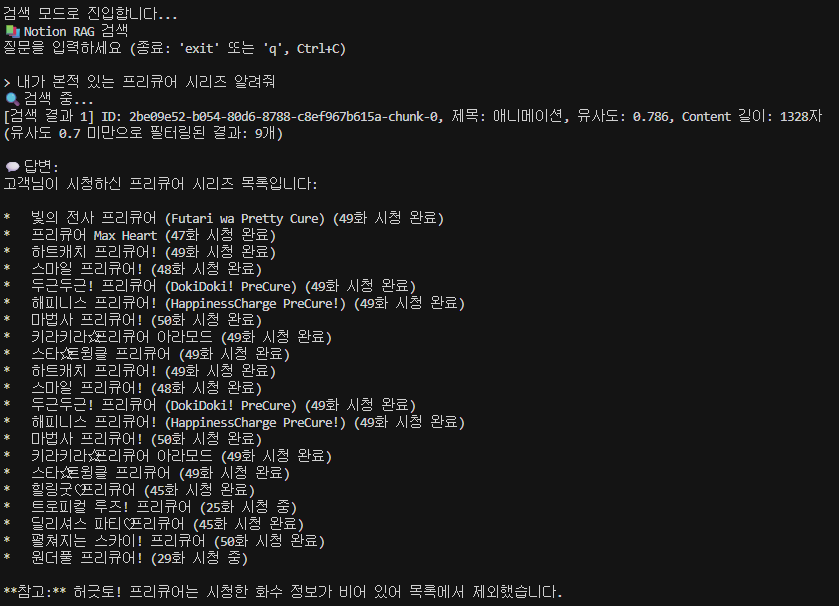
2가지 질문에 모두 적절한 대답을 하였음을 확인할 수 있습니다.
Go 언어로 직접 구현해 본 Notion RAG 프로젝트를 통하여 나만의 소형 RAG 시스템을 직접 구축해보고 사용해보는 경험을 해볼 수 있었습니다.
하지만 프로그램을 만들면서 아직 개선해야 할 과제가 많다는 것 또한 느낄 수 있었습니다.
테스트를 진행한 결과 추가 구현이 필요하다고 느껴진 부분은 다음과 같습니다.
기본 기능은 만족스러웠지만,확장 가능성을 생각하면 아직은 ‘초기 버전’이라는 느낌이 강했습니다.
아직 개선할 점은 많지만 오랫만에 흥미로운 프로젝트를 진행할 수 있었습니다.
개선과제를 정리하여 점점 개선해 보는 것도 재미있을 것 같습니다.
읽어주셔서 감사합니다.


