빌링 3.0

최근 안랩클라우드메이트의 SD파트는 '빌링 3.0' 서비스 고도화 작업을 수행하였습니다. SD파트는 이번 작업을 통해 서비스 오픈 후 발생한 대량 인보이스 발송 시의 성능 저하 문제를 분석하고 해결하였습니다. 예상치 못한 DB 쿼리 타임아웃, 커넥션 고갈, 외부 API 연동 지연 등 실제 운영 환경에서 마주할 수 있는 기술적 난제들을 복합 인덱스 생성, 커넥션 풀 설정 최적화, 프론트엔드 로직의 배치 처리 방식 도입 등을 통해 단계적으로 풀어나가며 트러블슈팅을 한 경험을 이번 포스팅을 통해 공유해보겠습니다.
SD 파트는 지난 해 가을 고객사를 대상으로 새로 개편된 빌링 포털 서비스를 오픈하였습니다. 서비스 오픈 후 몇 가지 예상치 못한 이슈가 있었는데요. 그중 하나가 매월 청구 시기마다 인보이스 200건 정도를 일괄 발송할 때 성능 저하가 발생하는 이슈였습니다. 여러 시행착오 끝에 성능 저하 이슈를 어느 정도 해결할 수 있었습니다. 관련해 1편에서는 발생한 문제 해결 방법을 먼저 알아보고 2편에서는 OpenTelemetry와 Azure Application Insights를 활용한 관측 가능성(Observability) 구축과 K6를 활용한 부하 테스트로 추가적인 문제를 미리 확인하여 개선한 사례를 소개하겠습니다.
당시 운영 중인 빌링 3.0에서 발생한 이슈는 매달 청구서를 발행할 때 발견되었습니다. 서비스 오픈 후 사내 청구 담당자가 발송 대상 청구서를 모두 선택해 일괄 발송을 진행했습니다. 그런데 오픈 전 테스트와 달리 대부분의 청구서 발행 및 이메일 발송이 정상적으로 처리되지 않는 문제가 발견되었습니다.
기존에 구현된 청구서 발송 로직은 건별로 따로 이메일 발송을 요청하는 형태였습니다. 오픈 전 10건 이하로 테스트할 때는 문제가 없었습니다. 그런데 실제 운영 환경에서 200건 이상을 동시에 요청하자 다음과 같은 복합적인 문제가 발생하며 정상적으로 처리되지 않았습니다.
● 건별 인보이스 데이터 조회 시 DB 쿼리 타임아웃 오류 발생
● 이메일 발송 시 SMTP 서버 업체의 전송 제한(Rate limit)으로 인한 발송 지연
● 이메일 발송 등에 필요한 사용자 및 고객사 정보 조회 시 DB 최대 커넥션 초과 오류 발생
원인을 파악하기 위해 인보이스가 발송되는 과정을 먼저 다시 한번 확인해 보았습니다. 당시 빌링 3.0에서 사용자가 발송할 인보이스를 선택하고 발송을 누르면 다음과 같은 작업이 수행되었습니다.
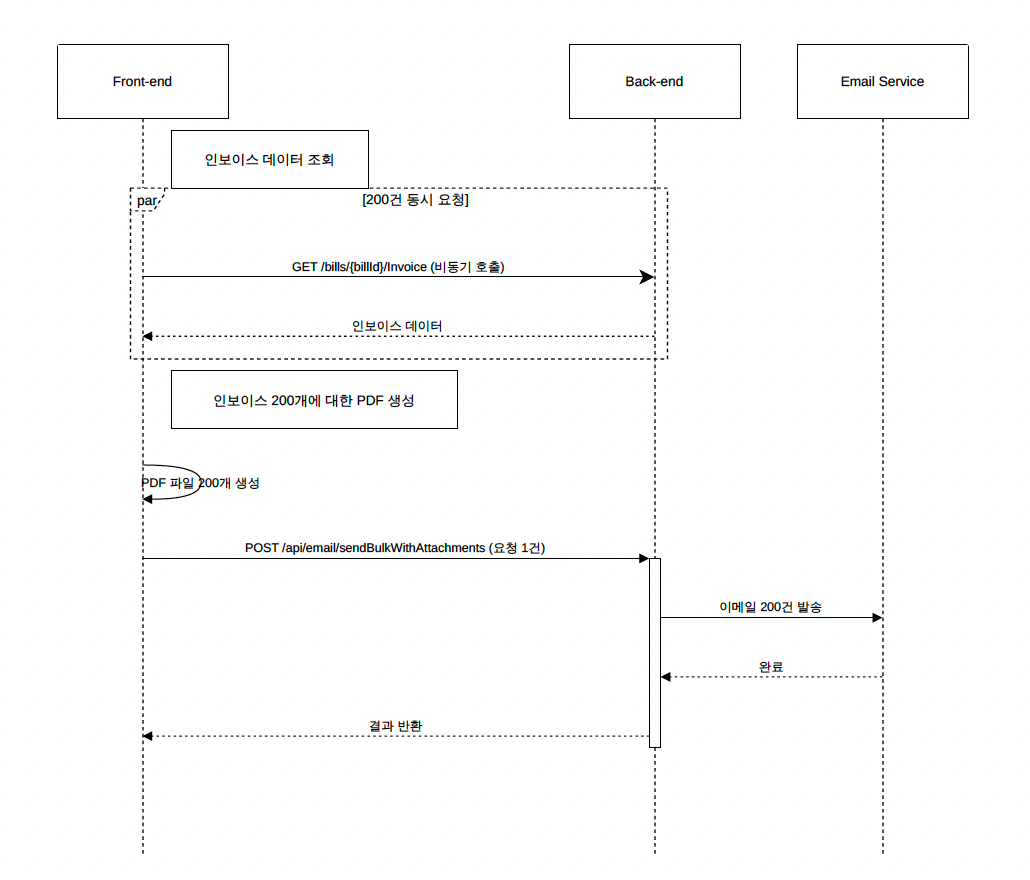
실제로 200건 정도를 선택해 실행해 보니 발송 단계에 진입하기 전 인보이스 조회를 동시에 여러 건 호출하면서 문제가 발생했습니다. 이전에도 10건 이하를 선택했을 때 조회가 수 초 정도 소요되긴 했으나 한번에 200건의 조회가 몰리자 쿼리가 정상적으로 수행되지 못하고 타임아웃이 발생한 것입니다. 이 문제를 해결한 후에도 실제 발송 과정에서 다시 오류가 발생했습니다. 발송 전 필요한 정보를 IAM에서 조회할 때 처음 수십 건은 처리되었으나 이후 응답이 지연되거나 IAM 측 DB에서 'Too many connection' 오류가 발생했습니다.
먼저 인보이스 목록에서 약 200건의 항목을 체크할 때 발생하는 대량의 API 응답 오류부터 해결하고자 했습니다. 이럴 때 흔히 검토하는 방안이 캐시 도입입니다. 브라우저 캐싱(ETag, Last-Modified)이나 서버 애플리케이션 메모리 캐시 또는 Redis 같은 인메모리 저장소를 활용하는 등 여러 방법이 있습니다.
하지만 결론적으로 캐시는 도입하지 않았습니다. 캐시는 자주 조회되는 항목을 메모리에 임시로 저장해 빠르게 꺼내 쓰는 방식인데, 매월 청구 주기마다 수행하는 대량 발송 작업은 매번 서로 다른 새로운 데이터를 조회해야 하므로 캐시 효율이 낮다고 판단했기 때문입니다.
대신 인보이스 조회 시 실행되는 쿼리를 개선하거나 테이블 구성을 수정하여 문제를 해결했습니다. 인보이스 정보를 조회하는 API는 여러 외부 API 호출과 쿼리를 수행하는데, 그중 가장 복잡하고 오래 걸리는 작업은 청구서 하위의 실제 사용 내역(NcpDetails) 여러 개를 조회하는 쿼리였습니다.
해당 쿼리는 Join 과정에서 사용하는 서브쿼리 안에 KeyId별로 그룹화한 뒤, 각 그룹에서 가장 최근 날짜(batchDate)를 선택하는 로직이 포함되어 있었습니다. 하지만 이 두 컬럼에 대해 별도로 설정된 인덱스가 없었습니다. 이로 인해 10건 이하일 때는 수 초 이내로 실행되었지만, 한번에 200건의 요청이 들어오면 쿼리가 정상적으로 실행되지 못하는 문제가 발생했던 것입니다.
따라서 아래와 같이 두 컬럼에 대한 복합 인덱스(Composite Index)를 생성하여 문제를 해결했습니다. KeyId로 먼저 그룹화하므로 이를 우선 배치하고, 그 안에서 최신 날짜를 찾기 위해 batchDate를 내림차순(DESC)으로 지정하여 인덱스를 생성했습니다.
CREATE INDEX [idx_NCP_Detail_KeyId_BatchDateDesc]
ON [dbo].[NCP_Detail] (
[KeyId] ASC,
[batchDate] DESC
);또 다른 문제는 인보이스 발송뿐만 아니라 고객사 사용자 일괄 초대 등 다른 API 호출 시에도 발생하는 DB 커넥션 고갈 문제였습니다. 주로 빌링 백엔드에서 IAM 서비스 API를 호출하거나, IAM 서비스에서 자체 DB에 쿼리를 수행할 때 발생하였으며 원인은 크게 두 가지였습니다.
첫째는 다수의 요청이 한꺼번에 몰리면서 발생한 물리적인 커넥션 부족이었습니다. 빌링 및 IAM 서비스 백엔드 양쪽에 요청이 집중되면서 MySQL의 기본 최대 커넥션 수인 151을 초과하여 'Too many connection' 오류가 발생했습니다.
둘째는 커넥션 반환 누수(Leak) 문제였습니다. IAM 서비스 백엔드에서 단순 조회 쿼리를 수행한 후 사용한 커넥션을 제대로 닫지(Close) 않아, 커넥션 풀에 자원이 반환되지 않고 계속 점유되어 이후의 요청들이 대기 상태에 빠지는 현상이 확인되었습니다.
이를 해결하기 위해 우선 MySQL 설정을 수정하여 커넥션 허용 범위를 상향했습니다. Ubuntu VM에 설치된 MySQL의 설정을 변경하여 최대 커넥션 수를 250으로 늘렸습니다. 평소에는 커넥션 수가 급증하는 경우가 없고 인보이스 대량 조회나 발송 같이 한시적으로 발생하므로 최대 커넥션 수만 수정하였습니다.
# /etc/mysql/mysql.conf.d/mysqld.cnf
# 기본값 151에서 250으로 수정
max_connections = 250또한, 빌링 3.0 백엔드 애플리케이션에서는 DB 연결 문자열 설정을 통해 Maximum PoolSize를 80 정도로 제한하여 커넥션 자원을 효율적으로 관리하도록 조치했습니다.
Server=<host>; Port=<port>; Database=<db>; MaximumPoolSize=80; Uid=<user>; Pw=<pw>;가장 핵심적인 원인이었던 IAM 서비스의 커넥션 누수는 코드 개선을 통해 해결했습니다. Go 언어로 개발된 IAM 서비스에서 db.Query를 사용해 데이터를 조회한 후, rows.Close()를 호출하지 않아 커넥션이 반환되지 않는 지점들이 발견되었습니다. 특히 쿼리 결과를 변수에 할당만 하고 실제로는 사용하지 않는 로직에서 이러한 실수가 잦았습니다. 예를 들면 다음과 같이 사용하는 것이 맞습니다.
//db.Query로 쿼리 실행
rows, err := db.Query("SELECT * FROM users")
//함수 반환 때 row.Close() 함수를 호출하여 커넥션 반환
defer rows.Close()실제로는 다음과 같이 rows.Close()가 누락되어 있었습니다.
// db.Query로 쿼리 실행
rows, err := db.Query("SELECT * FROM users")
if err != nil {
return err
}
// rows.Close() 호출 누락
return nil또한, 대부분의 경우 쿼리 결과가 반환되지 않거나 결과를 사용하지 않는 작업이어서 다음과 같이 반환된 Rows를 변수에 할당하지 않는 경우가 많습니다. 그래서 반환된 Row에 대해 Close를 호출하여 커넥션을 반환하는 것도 누락되는 경우가 많았습니다.
// db.Query 로 쿼리 실행
userid = 1
_, err := db.Query("delete from users where id = ?", 1)
if err != nil {
return err
}
// rows.Close() 호출 누락
return nil이 문제를 해결하기 위해 쿼리 결과 반환이 필요 없거나 사용하지 않는 모든 작업은 커넥션을 즉시 반환하는 db.Exec 방식으로 수정했습니다. 이 과정에서 GitHub Copilot과 같은 생성형 AI 도구를 활용하여 프로젝트 전체 소스 코드에서 동일한 패턴을 찾아 수정함으로써 작업 효율을 극대화할 수 있었습니다.
// db.Exec 로 쿼리 실행
userid = 1
_, err := db.Exec("delete from users where id = ?", 1)
if err != nil {
return err
}
return nil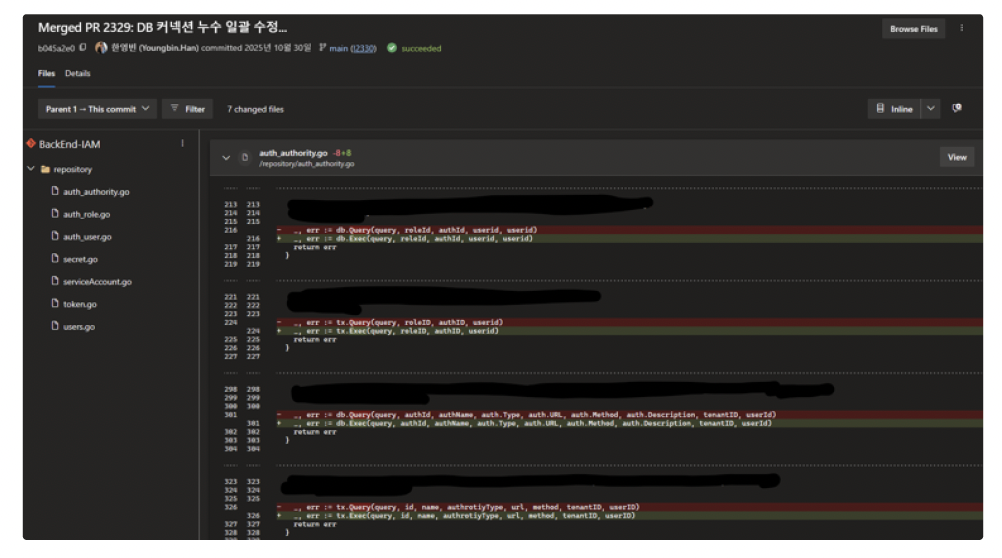
생각해 보면 매달 인보이스 발송 시 발생하는 이러한 문제를 해결하기 위해서는 인보이스 생성 및 발송 로직 전반을 수정하여 다른 방식으로 다시 구현하는 것이 가장 좋은 방법일 수도 있습니다. 현재는 프론트엔드에서 약 200건의 인보이스를 각 건별로 호출하는 작업을 한 번에 수행하고 각 PDF를 생성한 뒤 다시 백엔드 API를 호출하며 파일들을 전달하는 형태입니다.
아마 프론트엔드에서 처리하기보다 백엔드에서 요청을 받으면 별도의 백그라운드 작업 프로세스에서 인보이스 PDF 생성과 이메일 발송을 순차적으로 처리하도록 구현했다면 발송 속도는 다소 느려지더라도 이 글에서 언급한 문제는 발생하지 않았을 것입니다. 하지만 개발 당시 제한된 일정 내에 계획된 기능을 완성해야 하다 보니 기존 빌링 2.0에서 사용하던 코드 일부를 재활용하게 되었습니다. 이미 프론트엔드 중심의 구조로 서비스가 시작된 상태였고 당장 다음 청구 주기 전까지는 문제를 해결해야 했습니다.
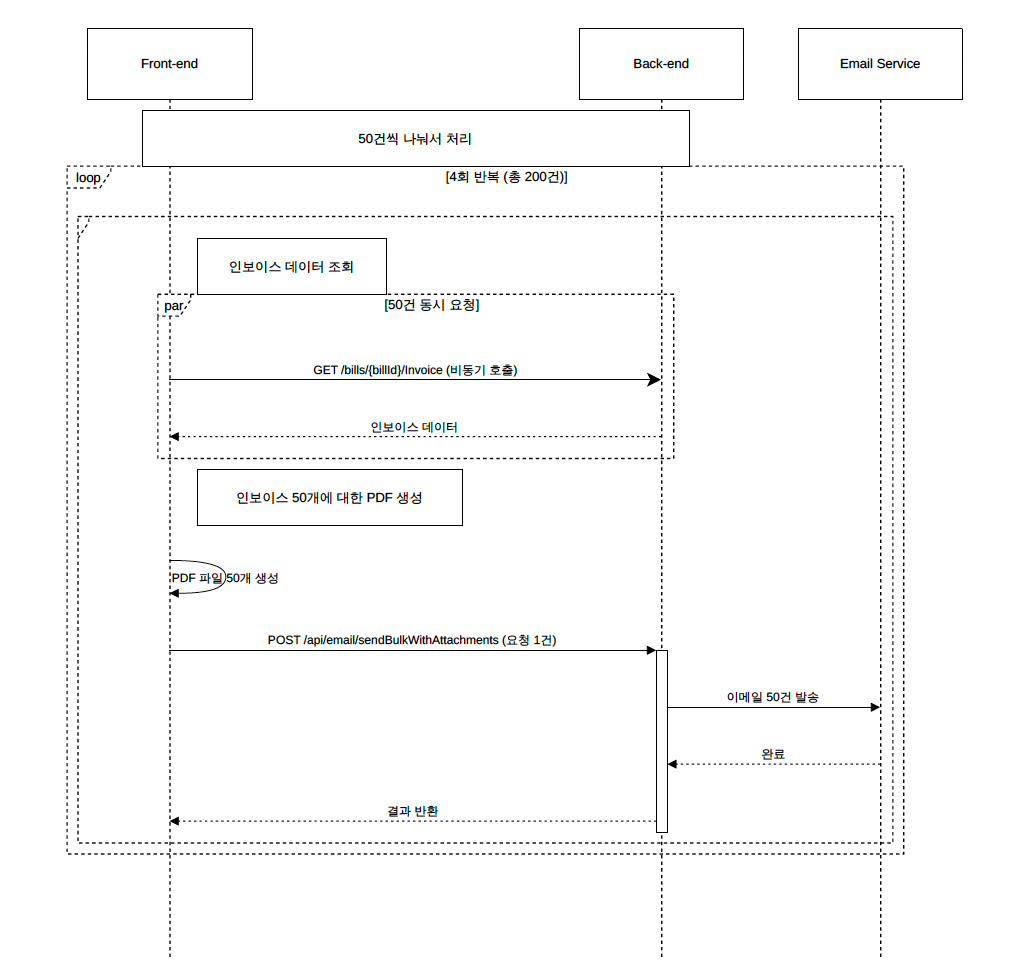
이에 따라 백엔드에서 성능 저하를 완화하기 위한 작업을 진행함과 동시에 빌링 3.0을 함께 개발하던 프론트엔드 개발자분들께도 몇 가지 개선 사항을 요청하였습니다. 고객사가 늘어남에 따라 백엔드 개선만으로는 한계가 올 수 있기에 프론트엔드 로직 수정에 대해 다음과 같은 사항을 제안하였습니다.
감사하게도 프론트엔드 개발자분들께서도 이러한 문제에 깊이 공감해 주셨고 제안드린 사항을 적극적으로 반영해 주셨습니다. 덕분에 다음 청구 주기가 오기 전 인보이스 발송 기능을 더욱 안정적으로 개선하여 적용할 수 있었습니다.
이번 빌링 3.0 출시 후 발생한 문제를 해결하면서 실제 서비스를 출시하면 개발 단계에서 예상치 못한 문제가 언제든 발생할 수 있다는 점을 다시금 배웠습니다. 특히 이러한 문제를 사전에 파악하거나, 설령 파악하지 못했더라도 문제가 터졌을 때 즉시 그 원인을 찾아낼 수 있는 환경이 얼마나 중요한지 절실히 느꼈습니다.
빌링 3.0뿐만 아니라 다른 서비스를 개발하면서도 늘 고민해 오던 지점이었습니다. 이에 따라 이후 빌링 3.0에는 OpenTelemetry와 Azure Application Insights를 활용한 관측 가능성(Observability)을 확보하고, k6를 활용한 부하 테스트를 도입하여 다른 기능상의 결함이나 성능 문제를 미리 파악할 수 있는 체계를 구축하고자 노력하였습니다. 이에 대한 구체적인 여정은 2편에서 자세히 다루어 보도록 하겠습니다.


